Some notes for running a local, multi-node Kubernetes cluster with k3d, and configuring it with nginx-ingress.
This is a useful approach to learn more about how the various components fit together, and to enable local testing without having to spin up a full blown Kubernetes cluster on a cloud provider.
Configure and Run K3d
Create a config file, k3d-conf.yaml.
Notable parts:
- ports: this will configure the provided nginx loadbalancer to be available on localhost port 8080
- k3s extraArgs: this will prevent the default svc loadbalancer being deployed to the nodes
apiVersion: k3d.io/v1alpha4
kind: Simple
metadata:
name: mycluster
image: rancher/k3s:v1.26.0-k3s2
agents: 3
ports:
- port: 8080:80 # same as '--port 8080:80@loadbalancer'
nodeFilters:
- loadbalancer
options:
k3s:
extraArgs:
- arg: --disable=traefik
nodeFilters:
- server:*
Then start up the cluster with:
k3d cluster create --config k3d-conf.yaml
Once started, inspecting the pods should show something like the following (note a lack of any traefik loadbalancers as we disabled them):

Install Nginx-ingress
Once the K3d cluster is up and running, install and deploy ingress-nginx via helm:
helm upgrade --install ingress-nginx ingress-nginx --repo https://kubernetes.github.io/ingress-nginx --namespace ingress-nginx --create-namespace

Once installed, inspecting the pods and services should show something like this:

The svclb-ingress-nginx-controller-* pods are created by K3s via a Service controller in reaction to the creation of the ingress-nginx-controller service.
Deploy a Workload
At this point a workload can be deployed, via a Deployment, Service and Ingress.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
environment: test
minReadySeconds: 5
template:
metadata:
labels:
app: nginx
environment: test
spec:
containers:
- name: nginx
image: nginx:1.17
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app: nginx
environment: test
type: ClusterIP
ports:
- port: 80
protocol: TCP
targetPort: 80
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: nginx-ingress
spec:
ingressClassName: nginx
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: nginx-service
port:
number: 80
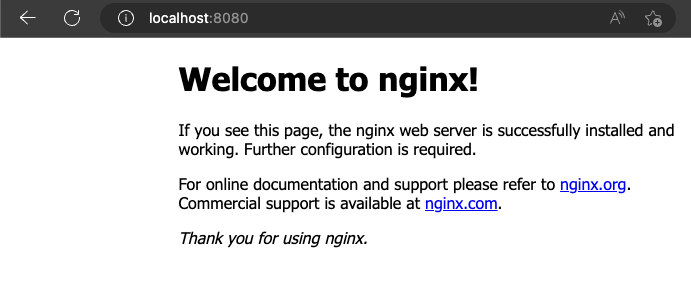
Lastly, navigate to http://localhost:8080 to ensure everything is working: